

But What About Reliability? The Kubernetes Cost Optimization Paradox

This post is the follow-up to Part 1: Save Millions on Your Cloud Bill, where we focus on the harder question: how do you apply those ideas in a real production environment without compromising reliability?
This article is based on a talk presented at KubeCon North America 2025. You can watch the talk here and view the slides here.
Special thanks to Zain Malik for his contributions to the ideas and work behind this talk.
Business leaders believe reliability can only be achieved at a high cost. There is some truth to this. Cut costs without considering reliability, and application stability takes a hit. Spooked executives abandon cost optimization to preserve customer trust. And you are back at sky high costs.
This is why every cost optimization initiative is met with the cautionary question:
But what about reliability?
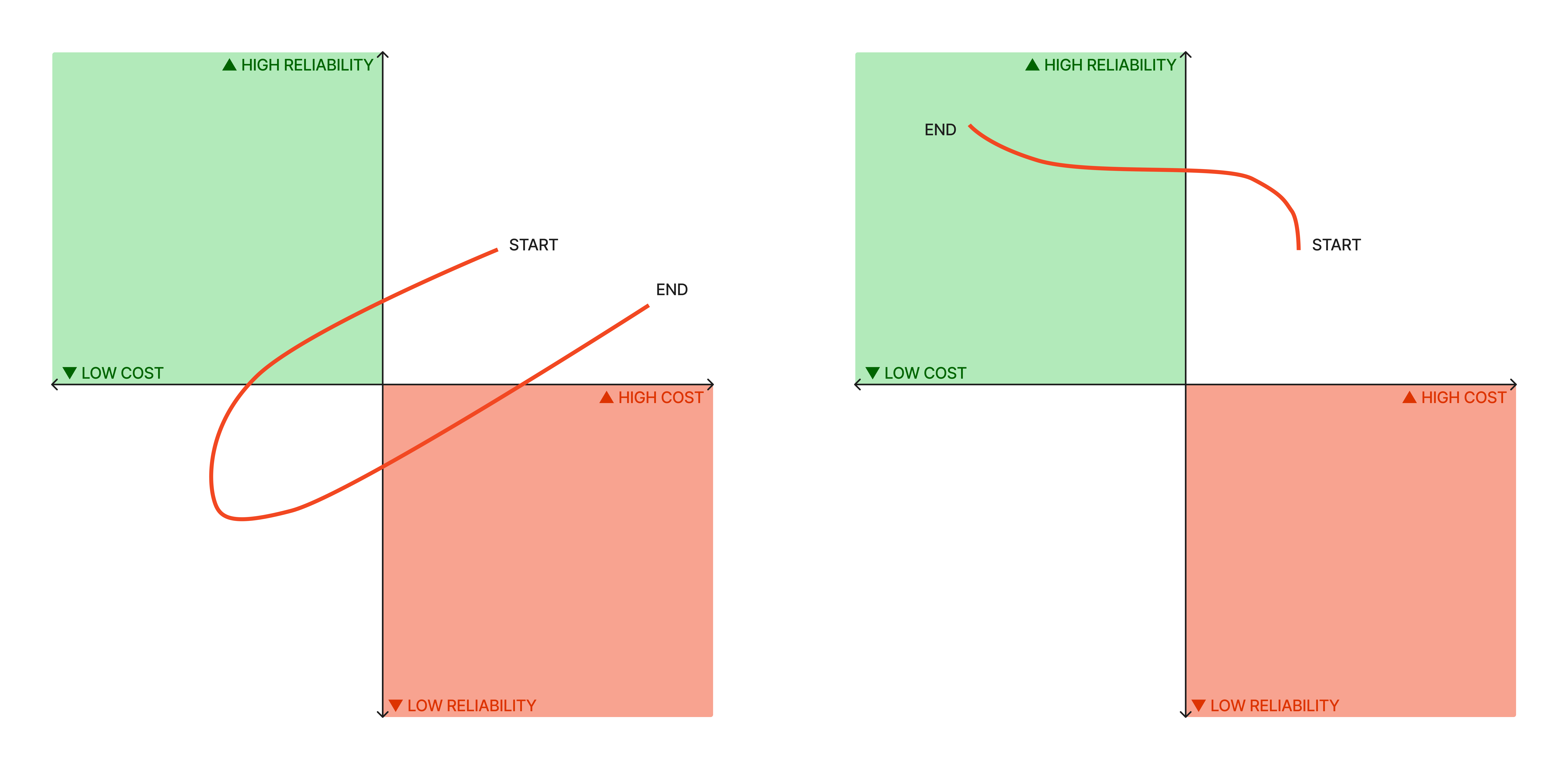
The fix is simple in principle: reliability needs to be an intentional step in reducing cost. The paradox isn't between cost and reliability. It's between fear and understanding. Once you understand the gaps in your reliability posture, reliability peaks and cost savings follow.
In Part 1 of this blog we laid out 11 strategies to reduce Kubernetes costs, starting from absolute basics like:
Use shared multi-tenant clusters
Enable Node Pool autoscaling, and ensure scale down to zero
Declare resource requests & limits for workloads
Use Horizontal Pod Autoscaling (HPA)
Intermediate techniques as your platform scales:
FinOps & cost visibility per team, per service, per namespace, etc.
Use spot nodes for ephemeral workloads
Align node shapes with workload demands
Enable custom metric-based autoscaling
And advanced techniques when infra cost justifies dedicated engineering:
Automatic request tuning for workloads
Custom scheduler for optimized bin-packing
Cluster Autoscaler expander profiles to scale across node pools
Enable controlled evictions to remove any eviction blockers
In this post, we show that cost optimizations done right actually increase platform reliability. This isn’t a contrarian theory. It’s a selection of war stories (along with technical solutions) from an organization operating cloud-scale Kubernetes infrastructure.
Technical Roadblocks
Each optimization technique from Part 1 comes with a reliability concern. Here’s how we addressed them by extending Kubernetes.
Protecting the Data Layer
Distributed databases like CockroachDB rely on quorum across regions. If multiple replicas are lost simultaneously in different regions, the database loses quorum or becomes inconsistent. This can take down every transactional service causing a serious global outage.
Evictions in different regions can happen for a myriad of reasons - Cluster Autoscaler (CA) scaling down an underutilized node, planned maintenance, node pool upgrades, etc.
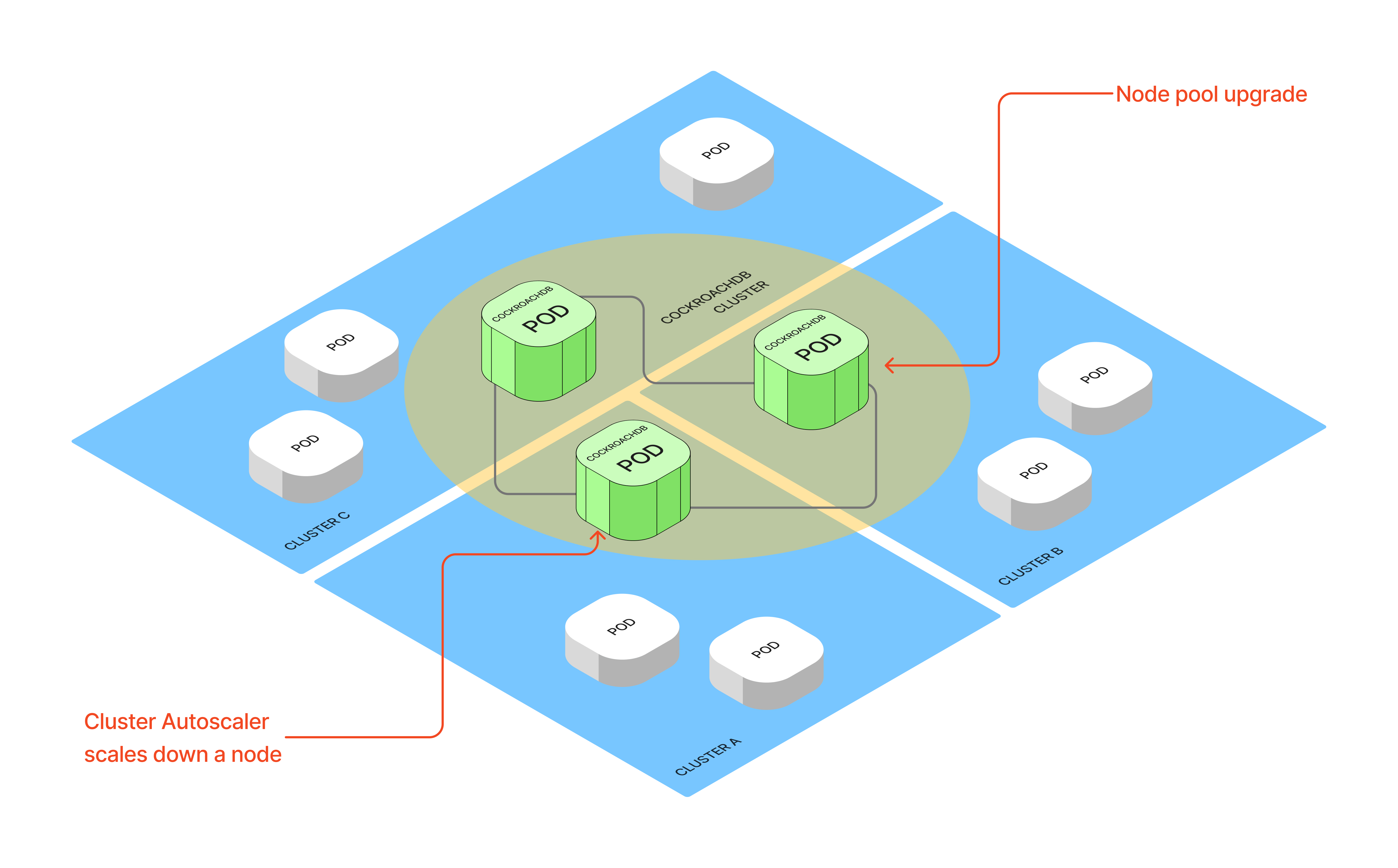
The instinctive response is to set PodDisruptionBudget (PDB) maxUnavailable to 0 on every CockroachDB pod. This feels safe. But nodes running CockroachDB pods can now never be drained. This isn’t just idle capacity burning money. It’s also an operational overhead because any node pool upgrade requires manual steps.
Solution
We built a multi-cluster distributed lock using the Kubernetes Leases API. The Leases API is typically used for leader election within a single cluster. We implemented a custom Operator extending Leases to coordinate evictions across clusters.
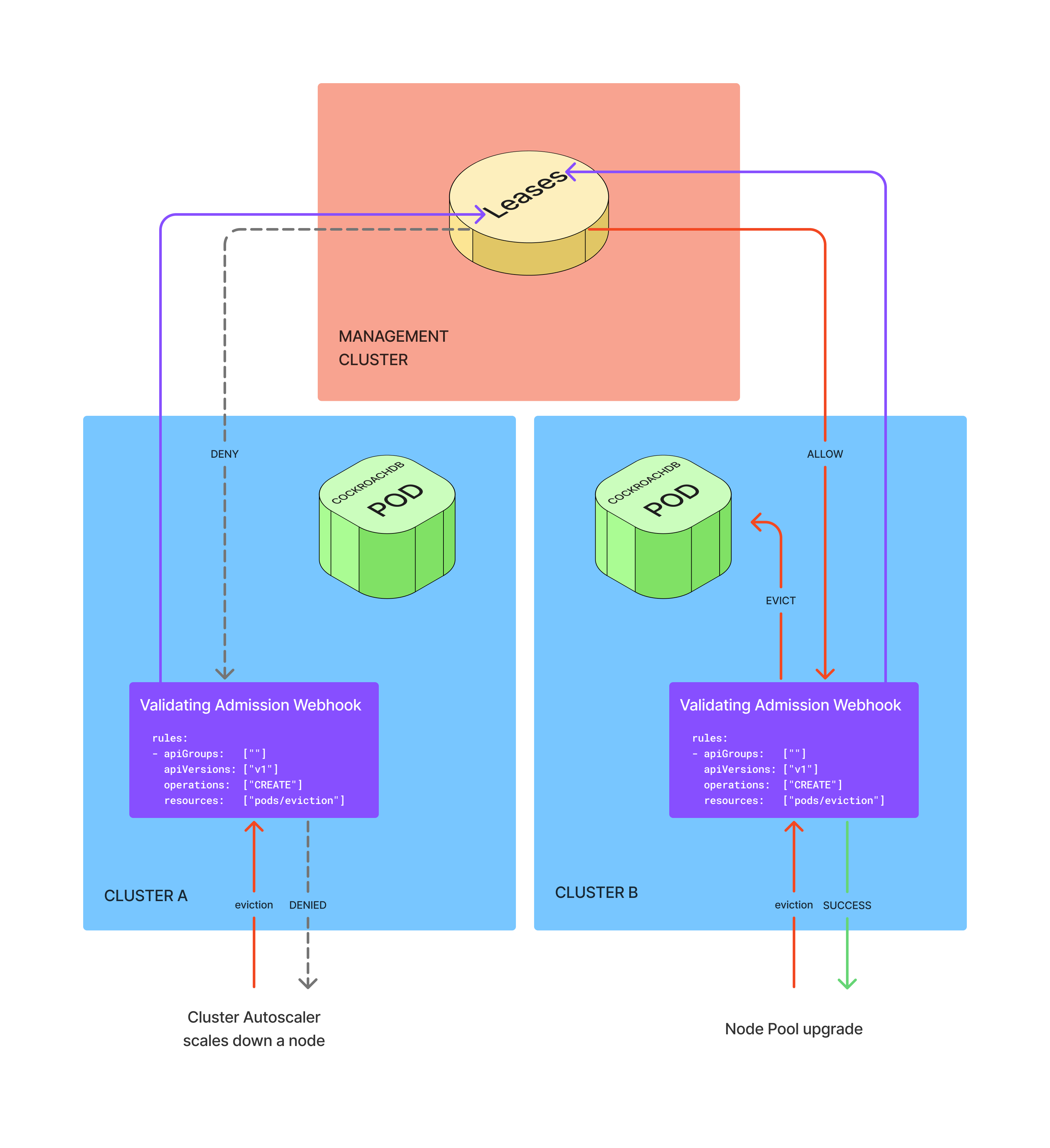
Before CA in any region attempts to evict a CockroachDB pod, it must first acquire a global lease. Only one cluster can hold that lease at any given moment. If a node pool upgrade in another cluster tries to evict a CockroachDB pod at the same time, it fails to acquire the lease and the eviction request is rejected.
This guarantees at most one CockroachDB pod is evicted globally at any given time. Quorum is never at risk.
By extending Kubernetes you can enable controlled evictions without a security blanket of overprovisioned resources. This gives you reliability and cost efficiency at the same time.
HPA vs. VPA
Horizontal Pod Autoscaler (HPA) and Vertical Pod Autoscaler (VPA) cannot be used together. This is a well-known Kubernetes limitation. Platforms that rely on horizontal scaling for reliability are forced to trade off automatically adjusting resource requests based on actual usage.
The instinctive response is to opt out of VPA entirely. Platform maintainers accept manually adjusting resource requests as an operational overhead. This doesn’t scale and leads to cumulative waste.
Solution
The key was figuring out how to use both HPA and VPA together. We built an automatic resource tuner to address this.
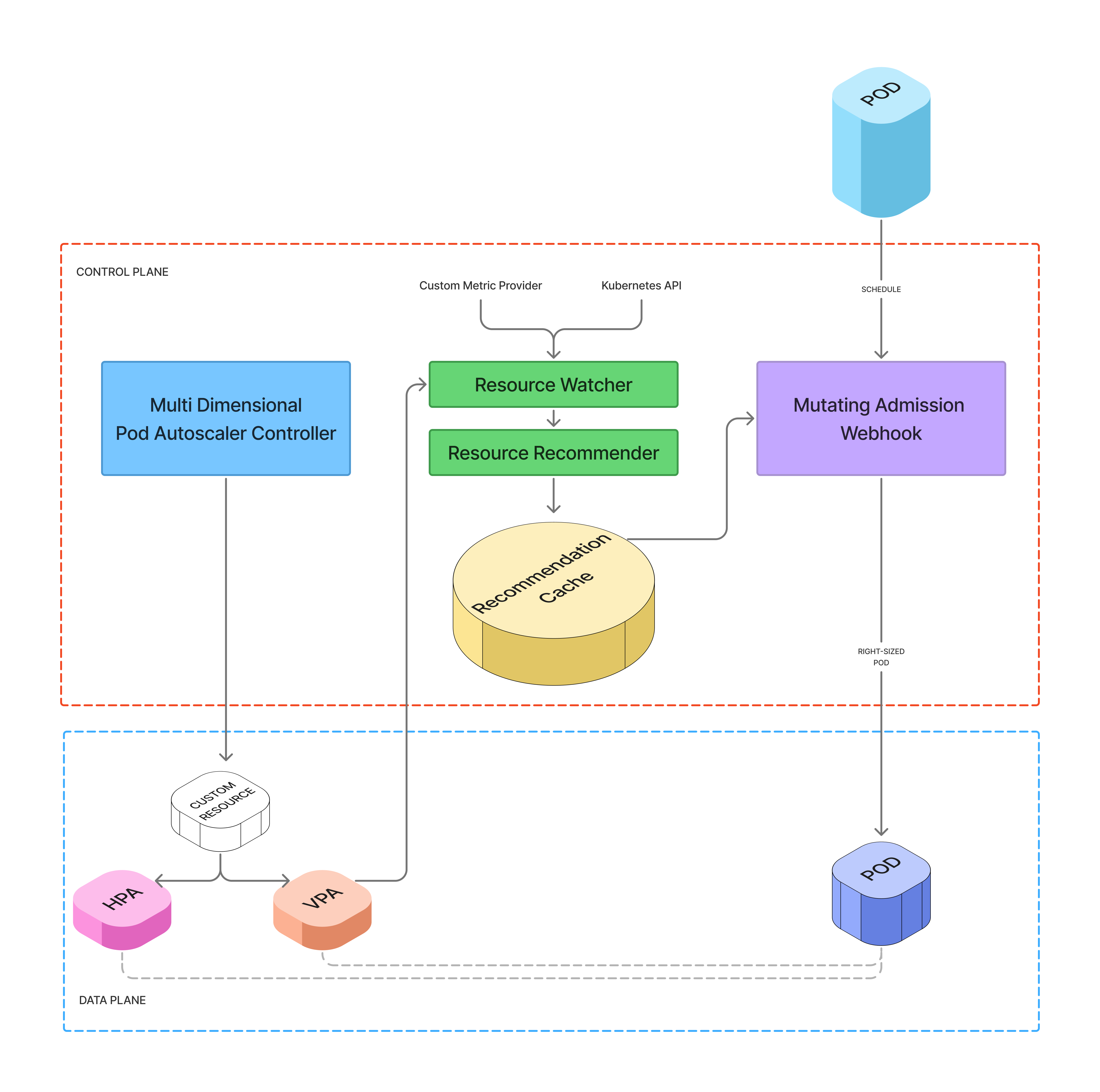
VPA in recommender mode analyzes usage and produces recommendations, but never applies them. We built a custom controller that blends these recommendations with a weighted average of usage data over the last several days. This produces a resource recommendation we can control - how frequently it gets generated, variance across regions, and overhead.
A Mutating Admission Webhook applies these recommendations at the next application rollout. We also built in self-service opt-in and opt-out mechanisms along with tuning profiles so developers can customize how their workloads get tuned.
When an upstream tool doesn’t quite fit your problem, the answer is often to extend it, not abandon it. Using HPA and VPA together by extending Kubernetes reduces both cost and operational overhead.
High Spec Node Flop
The instinctive path to reducing per-pod overhead is to use bigger nodes. Larger instance families like 96-core machines mean less amortized cost from DaemonSets, monitoring agents, network interfaces, and kubelet. More pods per node, lower overall cost. At least on paper.
In reality, cloud providers impose a max-pods-per-node limit. Without kernel level tuning you cannot pack too many pods on a node. These huge expensive machines end up half empty.
Solution
We reverted to smaller 32-core nodes and aligned node shape to the aggregate resource profile of our workloads. Our workloads were mostly memory-heavy. Across our fleet, memory would saturate first while CPU cores sat unused on nodes.
By switching from a 1:4 CPU to memory ratio to a 1:8, we packed pods more efficiently and reduced the gap between CPU and memory utilization. That’s where the savings came from.
Sometimes you have to dial back on a path that looks right on paper but doesn’t deliver in practice. When direct cost optimization isn’t possible, understand the real constraint before optimizing again.
The Flink Dilemma
Apache Flink powers critical ETL pipelines at most businesses. Some of these stateful stream processing jobs run for as long as 45 minutes or even hours. When moving workloads to Spot instances (up to 58% cheaper on most cloud providers) Flink is an obvious target.
The problem is that older versions of Flink didn’t support partial recovery or checkpoints. If a Spot node running a Flink job is reclaimed, the entire job restarts from scratch. This cascades delays to downstream systems and risks data inconsistencies.
The instinctive response is to optimize anyway and accept the occasional restart. 58% savings is hard to ignore.
Solution
We made a deliberate decision not to run Flink on Spot instances. The potential disruption cost overshadowed the potential cost savings.
Instead, we isolated Flink onto a dedicated on-demand node pool and explicitly allowed safe-to-evict: false annotations so these jobs won’t be evicted mid-execution. We accepted higher costs for one node pool. But this problem workload didn’t drag down the overall platform efficiency.
Sustained efficiency in a mature platform comes from knowing when not to optimize to protect reliability. If workload inefficiencies cannot be eliminated, isolate them instead.
Noisy Neighbor
Multi-tenant clusters mean workloads compete for shared resources. This is fundamental for cost efficiency, but comes with downsides. For example, a single pod throttling CPU on a node, or latency spikes from a memory-hungry neighbor.
When users cannot root cause these failures easily, “noisy neighbor” becomes the catch-all explanation. The instinctive response is to isolate workloads onto dedicated node pools or clusters. This is one of the most widely accepted arguments against multi-tenancy.
But isolation at that level destroys the density gains that make multi-tenancy worthwhile. You’re solving a diagnosis problem with expensive infrastructure.
Solution
We introduced Pressure Stall Information (PSI) metrics that tell users exactly how long a workload has been waiting for CPU cycles, blocked on I/O, or under memory pressure. A comprehensive node-level dashboard exposing CPU utilization, memory pressure, file descriptor counts, conntrack table usage, context switch rates, and per-workload PSI metrics lets engineers quickly identify what’s actually constraining their workload.
For workloads that genuinely need isolation, we introduced CPU core pinning via the Kubernetes CPU Manager static policy. This allows latency-sensitive workloads to request dedicated CPU cores on a node, eliminating context switching.
Noisy neighbor is almost always a visibility problem, not a multi-tenancy problem.
Cultural Roadblocks
Technical blockers are tough. Organizational resistance is harder. You can’t debug fear. You can’t automate trust. Dealing with people requires a different toolkit entirely.
FUD & Ownership
Engineers pour their careers into making their services stable. The idea of an automated system touching their workloads, let alone modifying resources on a schedule they don’t control, is genuinely frightening. This is a completely natural response.
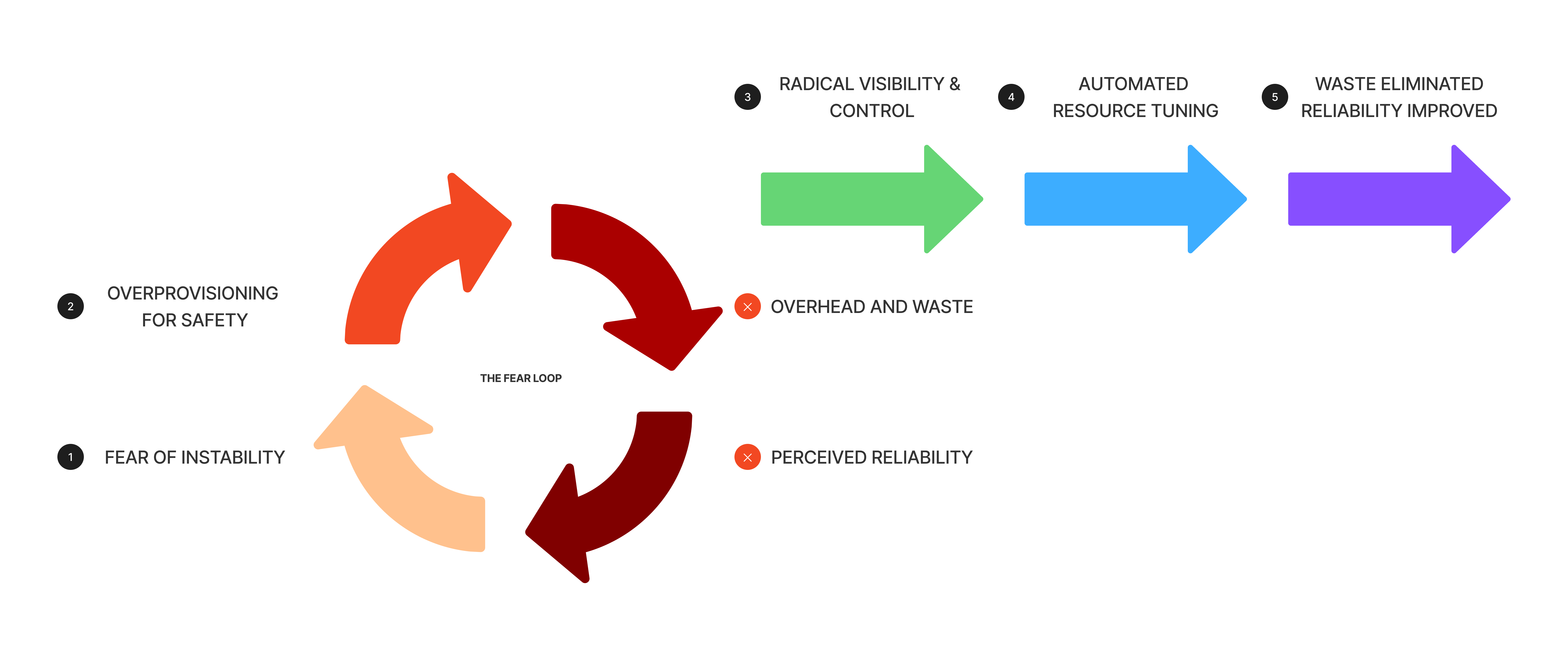
The instinctive reaction from leadership is to accept overprovisioning as an operating principle. Overprovisioning buys perceived reliability. Nobody gets paged for having too much headroom.
But perceived reliability isn’t actual reliability. It’s expensive guesswork. And it doesn’t scale. When we rolled out automatic resource tuning to over 1000 microservices, the biggest hurdle was pure Fear, Uncertainty, and Doubt (FUD).
Solution
We countered fear with radical visibility and control.
We gave developers dashboards showing exact CPU and memory usage vs. requested, alongside wasted dollars. Critically, we showed what the automatic tuner proposed to change those requests to. Automation was no longer a black box. Data replaced fear.
We also gave every team a self-service opt-out. A simple annotation to revert to their original requests without involving the platform team or raising a support ticket. No panic paging during an incident. This safety valve changed everything. Engineers trusted the automation more because they had the power to say no.
Break the fear loop with radical visibility and control. Build trust with data, transparency, control, and a little bit of empathy.
Sacred Workloads
Every organization has services that even the most prolific engineers refuse to touch. They are usually justified by high revenue generation, a big customer promise, or some historical outage story. These workloads run on dedicated hardware or have massive resource buffers.
The instinctive response is to not question it. If the service makes money and hasn’t gone down recently, leave it alone.
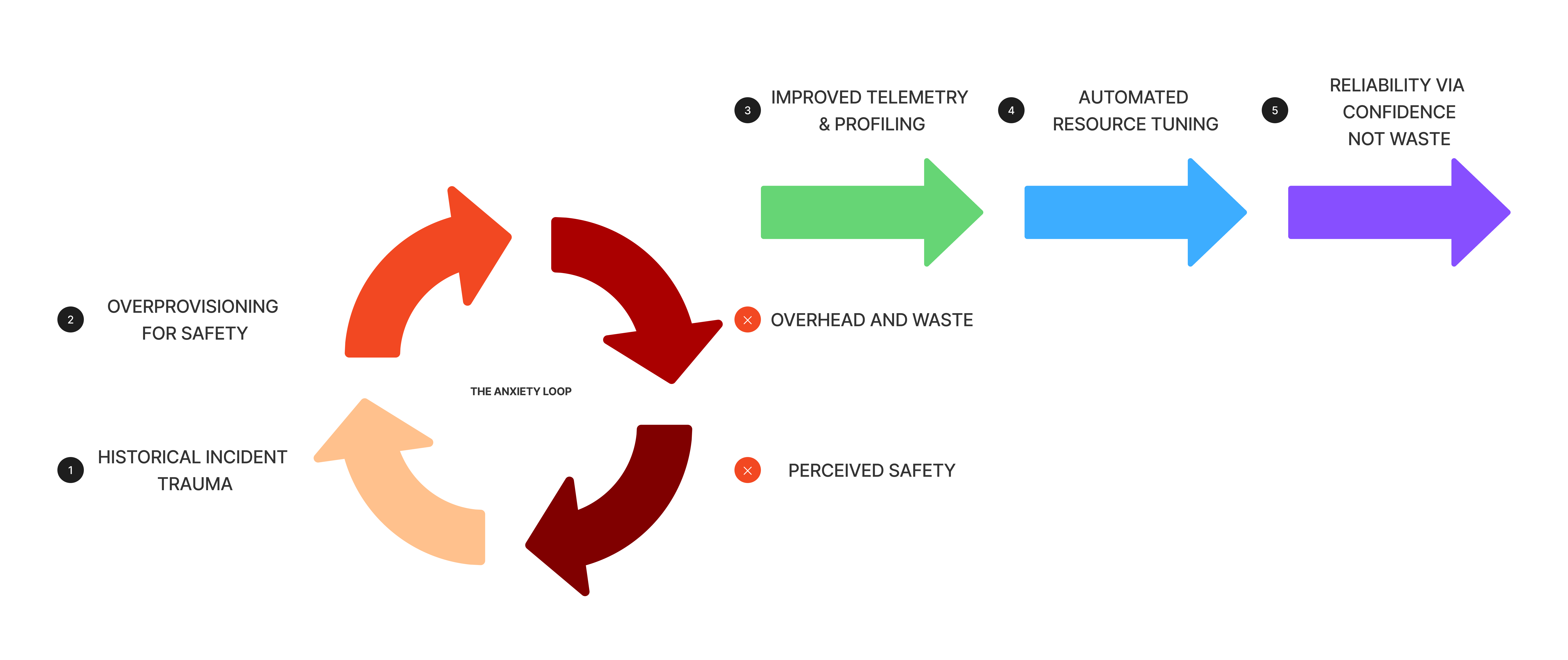
We had one critical transactional pipeline running with resource requests set at roughly 2000% of its average baseline usage. The team insisted it was imperative but couldn’t explain why. There was talk of “spikiness” and “rare edge cases” and historical incidents. But observability was weak, application behavior wasn’t well understood, and documentation didn’t exist. There was no technical truth to this overprovisioning. It just felt safer that way. Organizational scar tissue.
Solution
We invested in better metrics, traces, and profiling for these services first. We expanded developer tools so engineers could quickly take a heap dump from an application during a failure.
Once teams could actually see what the workload was doing, we could confirm whether it genuinely had unusual needs. In many cases, it didn’t. Teams were relieved to finally have data rather than anxiety. This enabled us to pull back the security blanket of overprovisioning from these sacred workloads.
Sacred workloads are sacred because people don’t understand them. When fear fills the knowledge gap, start with visibility, not optimization.
Eviction Blockers
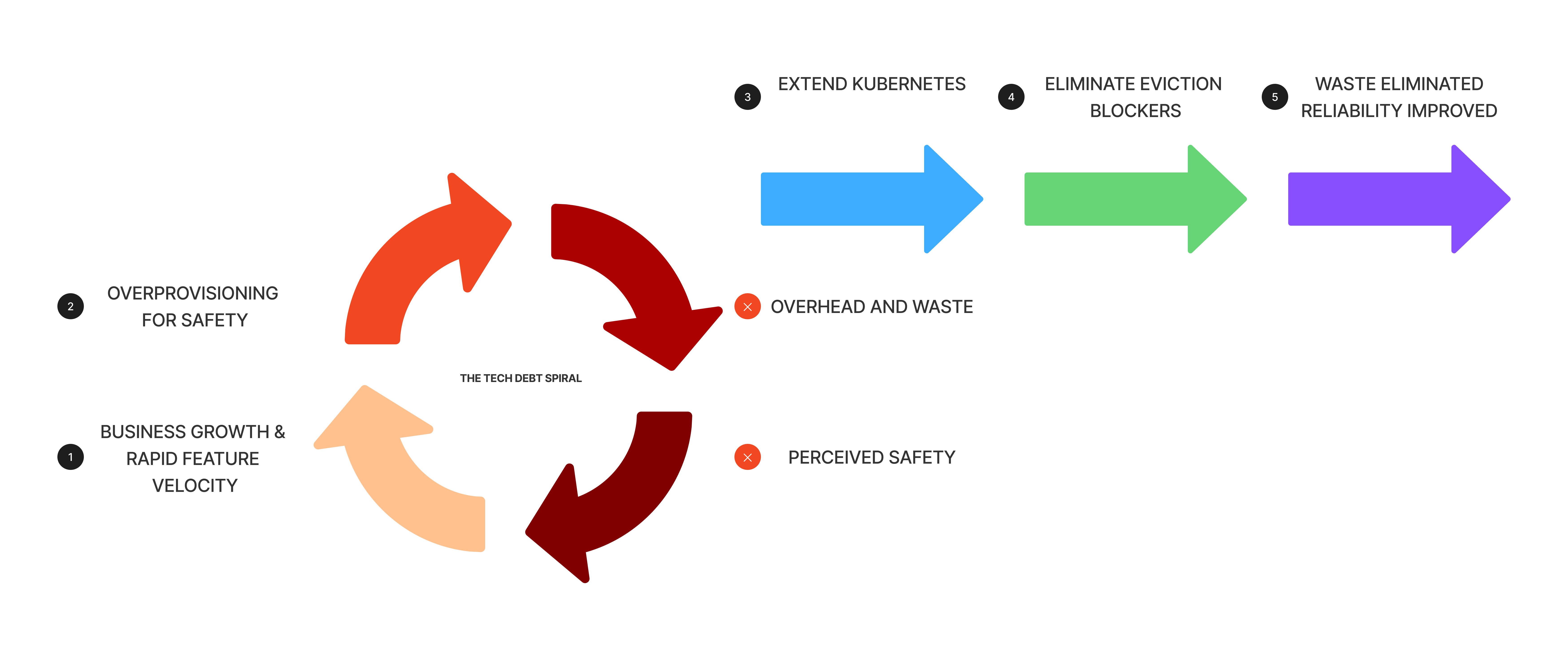
When a business grows fast, velocity wins over stability. Teams ship features and stability becomes tomorrow’s problem. At this inflection point we realized that 80% of nodes on our multi-tenant clusters had at least one pod blocking eviction. These workloads couldn’t handle shutdown signals gracefully without causing downstream business failures.
The instinctive response is to treat this as someone else’s problem. Application teams don’t want to rewrite shutdown logic. Platform teams don’t want to force changes that might cause outages. So the blockers stay.
This is a direct manifestation of organizational and technical debt. Even if workloads were tuned for optimal usage, the savings never materialized because these nodes could not be scaled down.
Solution
We introduced a Disruption Probe - a custom Validating Admission Webhook that gives developers full control over when a workload can shut down safely. The webhook intercepts eviction signals and executes a configurable program within the pod’s container before shutdown. Teams define what “safe” means for their service.
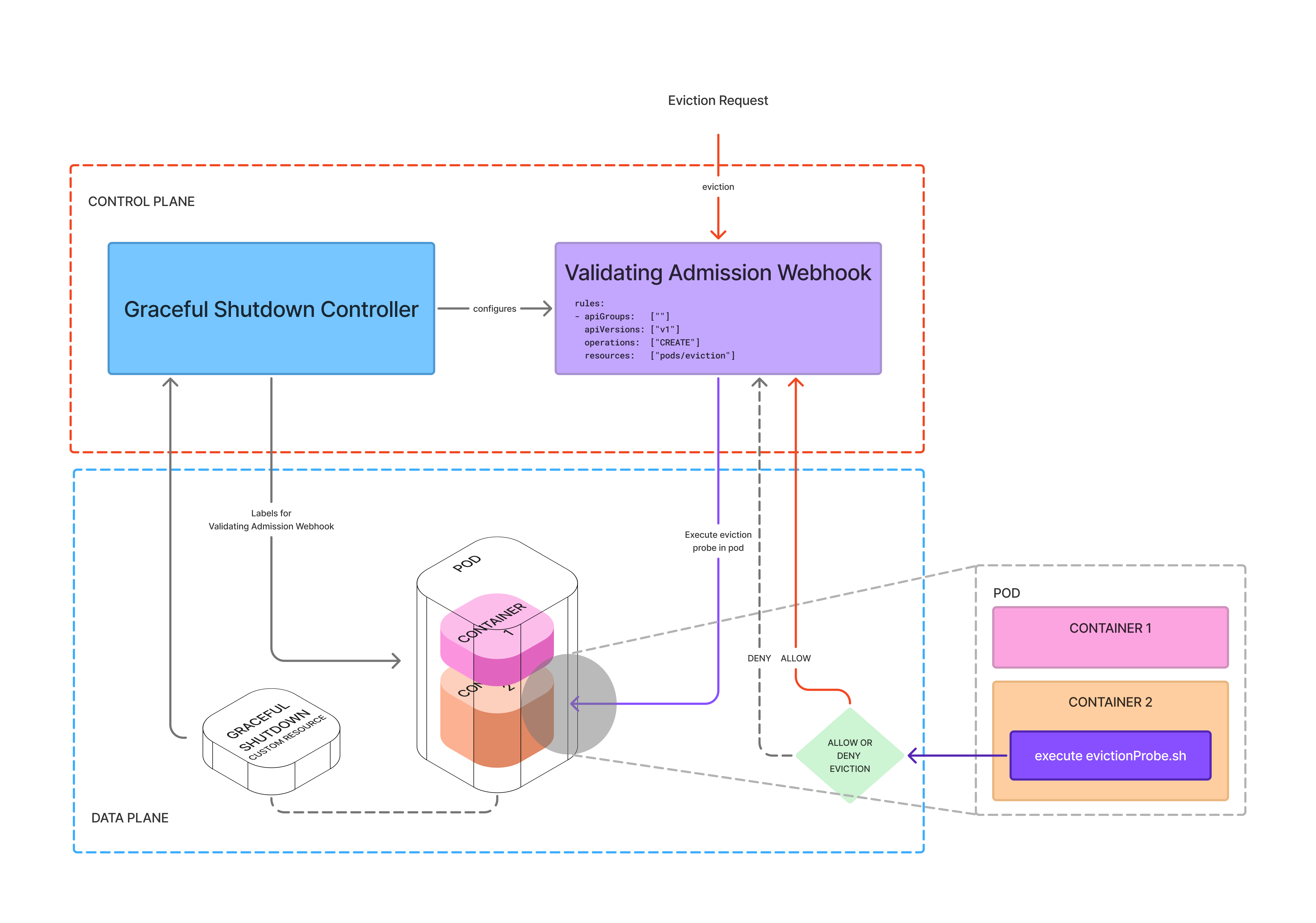
By giving developers control over eviction safety, the platform team no longer had to demand teams remove eviction blockers. Teams removed them voluntarily, without hurting reliability.
Organizational and technical debt is the cancer to any cost optimization effort. Technical innovation that gives developers control back is the only way to reliably cure it.
Personal Incentives
All the investment in automation, observability, and developer tooling won’t move the needle on your cloud bill if the humans responsible have no reason to care. Most engineering organizations reward technical novelty as a proxy for business impact. When efficiency isn’t rewarded, waste becomes normalized. The company’s bottom line takes a hit.
The instinctive response is to mandate cost optimization top-down. Leadership sets targets, platform teams enforce them, and application teams comply reluctantly.
This breeds resentment, not ownership. Mandates work until the next reorg or priority shift. Then waste creeps back.
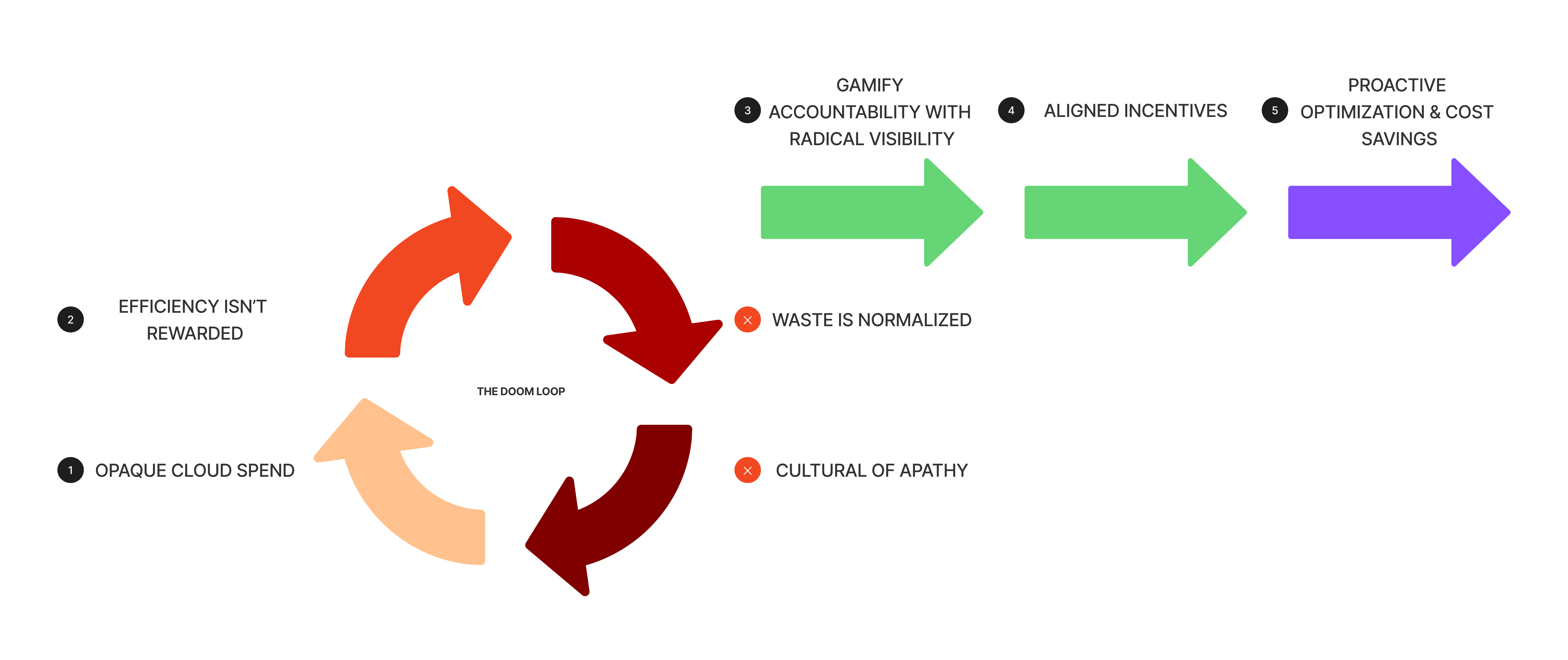
Solution
We changed the incentives.
The dashboards from automatic resource tuning evolved into leaderboards. Teams could see their waste ranked against others. Once waste became visible and measurable, positive peer pressure naturally kicked in.
Step two was making efficiency a formal performance dimension. Optimization results were folded into team goals, performance reviews, and bonus calculations for both engineers and managers. Once efficiency became personally consequential, the “don’t touch my workload” culture gave way to “how do I get my cost down?”
The most effective solution sometimes isn’t technology at all; It’s understanding human motivation to gamify accountability.
The Payoff
If there is one takeaway - you don’t have to choose between cost and reliability. You get both. But only if reliability is an intentional step in every optimization, not an afterthought. We reduced our annual cloud spend by 40%. Double digit millions saved per year. And our business reliability posture improved alongside it.
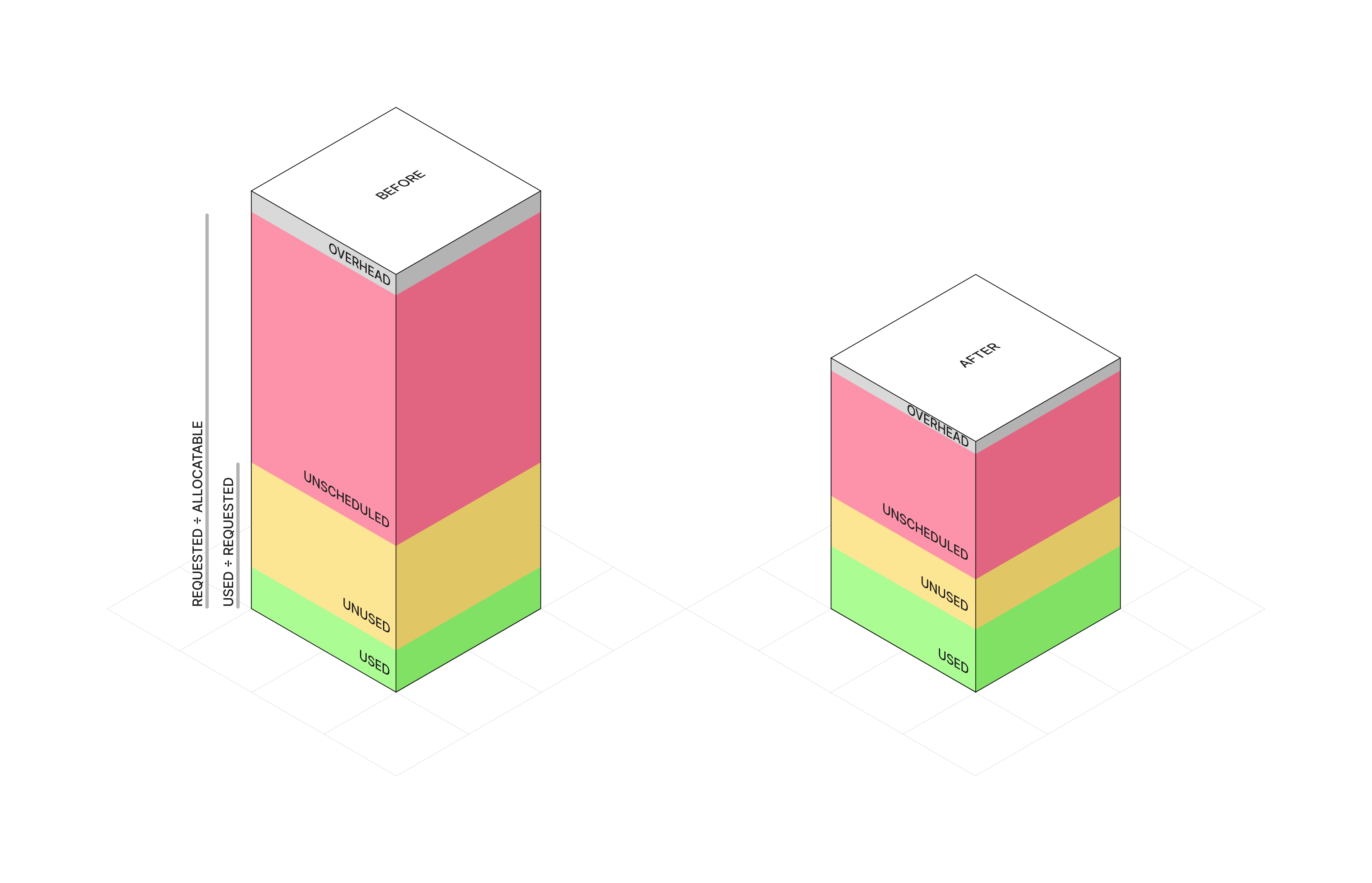
But progress wasn’t always linear. We tried bigger nodes and had to revert. We wanted Flink on Spot and had to say no. We rolled out automation and had to build escape hatches to earn trust. Success often comes down to how you handle the unexpected. Agility is key.
The process of optimizing cost forced us to build better tooling, deeper observability, and more resilient shutdown mechanisms. Every reliability concern in this blog was met with a technical solution that made the platform more resilient than before.
Kubernetes is not the end product. It is a framework for building platforms. By embracing its extensibility - writing custom controllers, configuring schedulers, leveraging APIs like Leases for novel purposes - you can transform it from a resource allocator into an intelligent, self-optimizing system. One that overcomes the cost of organizational fear.
Because the most expensive infrastructure isn’t compute. It’s fear.
Which tool was used to make these diagrams?